A File Server for NadaNet
Michael J. Mahon – April 27, 2007
Revised – October 24, 2008
Introduction
As I began to consider applications to run in parallel on the AppleCrate and AppleCrate II, I noted that many programs would require access to a file system for data input, output, and interprogram communication. AppleCrate machines have no attached I/O, except for NadaNet, so I decided to define a protocol to access files on a remote file server.
The resulting file server (FSERVER) can be accessed by any machine on the NadaNet, whether or not it has a local file system. This provides a convenient way to gain access to common files as well as a way to publish large volumes of data to other machines on the network. FSERVER can be found on the ProDOS boot disk.
Since NadaNet runs on both DOS 3.3 and ProDOS, as well as on the OS-less AppleCrate and AppleCrate II, the first design decision was whether the shared file system should run on the clients, or only on the server. In the interest of simplicity and conserving memory, I chose to have the file server present to its clients a subset of the BASIC.SYSTEM-ProDOS file system interface supporting only the "stateless" operations (e.g., no TEXT file support). This approach has the benefit of not requiring (but permitting) a file system to be present on the client machines.
Since the speed of the file server is dominated by the time to access storage devices and transfer data over NadaNet, Applesoft was chosen as the implementation language. The result is a program consisting of about 300 statements, totaling about 8KB in size (including lots of comments). In practice, performance has turned out to be more dependent on Applesoft than I hoped (more detail in the Performance section).
File Server Operation, Client side
When the file server and message server are running, any machine on the NadaNet can use the server's ProDOS file system by invoking the standard interface routine like this:
RQ$ = "bload myprog,a$2000" : gosub 51000
Of course, the request string can be formed by performing string operations to set up variable parameter values, etc., as desired.
The ProDOS command string may include either relative pathnames or absolute pathnames, so all parts of the server’s device/file space are accessible. The file server is trusting, so no protections are enforced. A reasonable convention to minimize naming conflicts would be to CREATE a subdirectory to hold subsequent files and concatenate that prefix to subsequent filenames.
The standard client interface code prefixes its machine ID (ID$) to the request and then queues it by doing a &PUTMSG to the predetermined file server queue number (16), then idles in a &SERVE#() loop polling the result code at a fixed location of 608 ($260) until it changes from the "in process" state of 127 ($7F). When it finds a change, it returns from the GOSUB and continues execution (unless an error was trapped).
IF the calling program sets EH=0 before issuing a request, a return indicates a successful request completion. Default error handling results in an error message and a STOP if something goes wrong.
If the programmer instead wants to handle errors in-line, EH can be set nonzero prior to the GOSUB. After the GOSUB, the value of RC should be examined to determine the actual error. A result code of 128 ($80) indicates that the request was completed without error. Any other value indicates that a ProDOS or Applesoft error occurred during request processing. The standard error codes are as defined in the publication BASIC Programming with ProDOS. The "incomplete" (127) and "complete without error" (128) codes were chosen so as not to conflict with the standard error codes. Note also that NadaNet defines one additional Applesoft error code, 49 (Data Error), which is caused by the failure of any NadaNet ampersand command.
The actual Applesoft client interface code consists of an initialization part and a request invocation part. Both are easily added to a program by EXECing the file FSERVER.EXEC with the client program in memory. A client program should GOSUB 50000 to the initialization code prior to any file server operations. The actual initialization code is:
50000 REM ====== File Server definitions ====== 50010 ID = PEEK (3 * 256 + 12 * 16 + 12): REM My NadaNet ID ($3CC) 50020 ID$ = CHR$ (ID): REM My ID as CHR$ 50030 IS$ = STR$ (ID): REM My ID as STR$ 50040 FSRV = 16: REM Msg Class of File Server Requests 50050 RA = 2 * 256 + 6 * 16: REM Result Code address = $260 50060 : 50070 REM Install USR function to return address of param 50080 I = 3 * 256 + 11 * 16: REM USR code at $3B0 50090 POKE 12, INT (I / 256): POKE 11,I - PEEK (12) * 256: REM USR JMP 50100 READ A$: IF A$ < > "USR" GOTO 50100: REM Position to USR DATA 50110 READ V: IF V > - 1 THEN POKE I,V:I = I + 1: GOTO 50110 50120 DATA USR,160,2,177,131,72,136,177,131,168,104,76,242,226,-1 50130 RESTORE 50140 RETURN
Note that the USR() function is defined by a short machine language program at $3B0 that returns the address of its string parameter. The code that POKEs this program into page 3 uses DATA by "scanning" for "USR", then READing the code, followed by a RESTORE. This approach allows this initialization code (and its DATA statement) to be toward the end of the program, even though it will be the first data needed. The RESTORE puts the DATA pointer back so that any earlier DATA statements will be seen by READs as expected.
The values of ID$, FSRV, and RA are used by the request invocation code, which is:
51000 REM ====== Invoke File Server ====== 51010 MS$ = ID$ + RQ$: REM Prefix ID 51020 POKE RA,127: REM Mark incomplete 51030 & PUTMSG(2,FSRV, LEN (MS$), USR (MS$)): REM Enqueue request 51040 FOR UNTIL = 0 TO 1 51050 & SERVE#():RC = PEEK (RA) 51060 UNTIL = (RC < > 127): NEXT : REM Await result 51070 REM RC = 129 means BRUN loaded code without error, now call it. 51080 IF RC = 129 THEN RC = 128: CALL PEEK (RA + 1) + 256 * PEEK (RA + 2) 51090 IF RC = 128 OR EH THEN RETURN : REM If OK or inline error handling 51100 PRINT "File server error "RC" for request:": PRINT "<"RQ$">" 51110 STOP
This code prefixes the request string with the NadaNet ID of the requester (so that the server will know where to send the result), sets the result code to "incomplete" (127), and enqueues the message on the message server queue polled by the file server.
It then enters a loop in which it serves the net, so it can respond to NadaNet operations initiated by the file server (or any other machine), until the result code changes from "incomplete". This is done with a FOR loop coded as a DO..UNTIL loop. While this may seem needlessly tricky, there is a good reason (which, as you can guess, I encountered during testing).
If a program wishes to RUN a program at a different start location than the current one (usually the default is $801), it does so by POKEing the new start location into page zero locations 103 and 104, POKEing a zero into the byte preceding that address, then calling DOS or ProDOS to perform the RUN. This works as long as the calling program does not do a branch that requires searching the text of the BASIC program between the POKEs and the RUN request, because doing so would fail if the pointer has been changed and a zero may have been POKEd into the middle of the running program! In particular, backward branches (GOTO loops) always require such a search. Only a FOR loop does not search the text of the program to close the loop (it stacks the pointer to the top of the loop).
Since the requesting code loops waiting for a completion code, a FOR loop must be used to prevent a failure if the program start pointer has been modified for some purpose.
Also note that the special return code value of 129 is used momentarily to indicate that a BRUN was processed, to cause the actual CALL of the binary program to be made synchronously by the requesting program, prior to RETURNing to the point of the GOSUB.
If an abnormal result occurs and the program has not indicated an intent to deal with it by setting EH=1, then the failure is reported and the program is terminated.
File Server Operation, Server side
The file server (FSERVER) idles in a loop polling its predetermined input message queue (16) with a &GETMSG, and &SERVEing the network. When it finds a request, it parses it, determines any unsupplied but needed parameters, and executes the command on the server’s ProDOS file system.
If a command requires a data transfer, it is &PEEKed from the client and BSAVEd, or BLOADed and &POKEd to the client. The buffer for file system operations is 16KB to minimize the number of file operations for large files. Network transfers are done in 1KB chunks to keep network latency for other users reasonable (more detail on this point in the Performance section).
After each command is completed by the server, it &POKEs a result code to the client (with error code, if any), plus the AUX TYPE and EOF of the file if data was transferred. After reporting completion status, the server loops back to check its input queue again.
Supported Command Syntax
The file server handles BSAVE, BLOAD, BRUN, SAVE, RUN, CREATE, DELETE, LOCK, UNLOCK, RENAME, and VERIFY commands, with their parameters. There are also two control commands: MON, to control monitoring of requests on the server’s display, and STATS, to read various statistical counters kept by the file server.
The syntax of the supported ProDOS commands is identical to their normal "local file system" forms, with only two exceptions:
The two "control" commands are used in the following way:
|
MON [n] |
If n is zero or omitted, monitoring output to the server’s display is turned off. |
|
If 0<n<100, then requests from the machine whose ID is n are monitored. |
|
|
|
If n>=100, then requests from all machines are monitored. |
|
STATS |
Causes the file server to &POKE its statistical counters into the area following the result code. The definition of counter area fields is: |
|
Address |
Size |
Description |
|
|
$260 |
608 |
1 |
Result Code (128 = no error) |
|
$261 |
609 |
1 |
File Server NadaNet ID |
|
$262 |
610 |
2 |
Total number of requests |
|
$264 |
612 |
2 |
Total number of errors |
|
$266 |
614 |
2 |
Total number of read requests |
|
$268 |
616 |
4 |
Total number of bytes read |
|
$26C |
620 |
2 |
Total number of write requests |
|
$26E |
622 |
4 |
Total number of bytes written |
Unsupported Commands
The OPEN, CLOSE, READ, WRITE, APPEND, FLUSH, POSITION, and EXEC family of text file commands are omitted because they would require keeping significant state on the server, necessitating a "session"-style connection. In my own programming, I have generally been able to use binary file I/O in place of text file I/O.
Unsupported commands were omitted either because they, too, require state (like PREFIX), because they require local processing that is not currently supported (like CATALOG, CHAIN, STORE, and RESTORE), or because they do not make sense for a remote Applesoft client (like LOAD, PR#, IN#, FRE, and BYE). The dash command ("-") was not supported because it includes EXEC, and is otherwise redundant.
Performance - Idle Network
At the outset, I expected performance to be limited primarily by device latency and bandwidth and by network bandwidth (>10KB/sec), and that the speed of the file server code would not be a major part of the equation. As it turned out, this was not the case.
In my first BASIC implementation, I used a simple scanner with nested GOSUBs to collect the comma-delimited parameters of a request, one character at time. My development machine is an Apple //e with an 8MHz Zip Chip, so it was easy to overlook the inefficiency of this approach. But with the machine running at a standard 1MHz, I found that scanning was taking about a second and a half per request!
After briefly considering writing a machine language scanner, I realized that Applesoft already has a facility for scanning comma-delimited strings--the DATA and READ statements. If I could use this mechanism, most parameters could be dealt with as strings instead of a character at a time (hex numbers being the only exception--I really wish that Applesoft had hex number support).
So I set about learning how to get the DATA scanner to do what I wanted. As it turns out, it's pretty easy. It is only necessary to POKE the data pointer at $7D.7E to point one character before the first character in the buffer to be scanned, and to POKE three zeroes after the end of the data (one flags the end of the "statement" and the other two signal end-of-program, so the scanner doesn't scan upward through memory looking for another DATA token!).
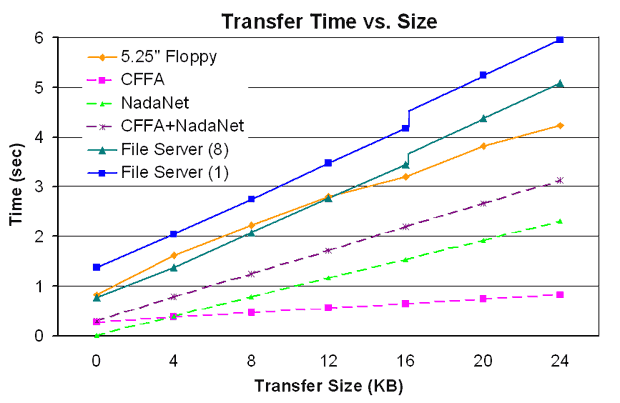
The result of changing the scanner in this way was a 3x improvement in scanning speed, or, put another way, a one second saving in processing each request! The perfomance profile of the faster version is shown in this graph of total time required vs. file size:
The graph shows the time taken to complete a BLOAD of various lengths in several different ways. The primary comparison point is the solid orange line, showing how long a 5.25" floppy requires to load the files. It is quite generous to the floppy drive, because it was measured by doing twenty BLOADs and dividing the total time by twenty. This has the effect of reducing the effect of the drive startup delay by a factor of twenty, but it seems a fair "busy system" measure.
The other two solid lines show the time taken to perform the same BLOAD using FSERVER at 1MHz (blue) and 8MHz (dark green). As you can see, the file server compares quite well with floppy access, with even the 1MHz times being comparable if the floppy has to start up each time. The discontinuities in the file server times at 16KB show the incremental time required for the server to do another BLOAD every 16KB because of its internal buffer size.
It's worthwhile to note that the inverse of the slopes of the graph lines shows the bandwidth of each of the file access methods after subtracting fixed overhead. The CFFA leads the pack at 44.4KB/s, NadaNet is next at 10.5KB/s (with unlimited chunk size), and the Apple 5.25" floppy turns in a very respectable 7.7KB/s. (The "wiggles" in floppy performance are caused by the BLOAD either missing a revolution or "hitting it right".) The file server, using a CFFA, delivers about 5.7KB/s to clients. All of these transfer speeds are affected very little by processor acceleration.
The dashed lines show the raw speeds of the CFFA, NadaNet, and the CFFA plus a NadaNet data transfer. This latter sum represents the limiting performance of the file server if the code were infinitely fast, as might be approached if it were coded in machine language. The limiting speed improvement that could be expected (and which would not be fully realized) ranges from about 4x for small files to only 1.5x for large files--a relatively small payoff for recoding it all in assembly language. For now, the Applesoft version is fast enough.
As mentioned earlier, though NadaNet does not impose an upper limit on the size of a data transfer (except memory size), long data transfers increase the network latency for all other users. Therefore, it is desirable to choose a maximum "chunk" size for NadaNet data transfers that minimizes NadaNet latency while maintaining good average bandwidth. The graph below shows the results of varying the chunk size for a relatively large file size (16KB):
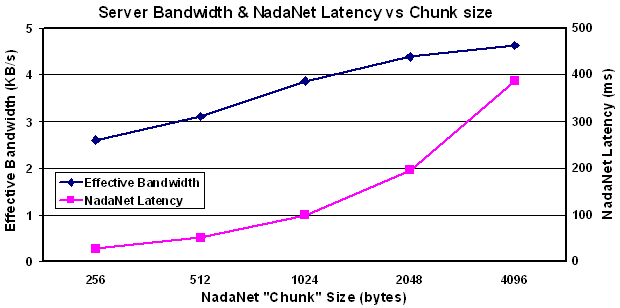
As you can see, the impact on network latency doubles as chunk size doubles, but the bandwidth rises toward an asymptote, so 1024 bytes was chosen as a compromise chunk size for this version of the file server.
Performance - Busy Network
All the performance numbers so far have been for the file server and a client running without any other traffic on the network. As a check on the efficacy of breaking the file server's network data transfers into chunks, I decided to do some "busy network" tests.
A good network load is provided by the NadaNet test program RAND.MSG.20, on the ProDOS NadaNet Startup disk. This program is PRUN on seven machines, plus a message server. Each of the seven machines accepts 20-byte messages from its input queue on the message server using &GETMSG. One byte in this message is tested, and if it is less than 255, it is incremented and the message is passed on to the queue of a random machine (using &PUTMSG). The queues of the seven machines are "primed" by the master machine with 5 messages having a serial byte=0.
As the parallel test program runs, each of the five times seven messages is passed on 256 times, for a total of 8960 &PUTMSG/&GETMSG pairs, or 17920 separate NadaNet messages. When run without additional load on the network, it completes passing all messages within about 132 seconds, for an average network message rate of about 136 messages per second.
When the random message test is run with a file server "busy" test that constantly BLOADs a 16KB file, the message test requires about 205 seconds to finish, for an average message rate of about 87 messages per second. So running the file server--on the master machine, with highest arbitration priority--causes about a 36% reduction in message rate.
Conversely, if we look at the impact of network message traffic on file server performance, we find that the time to perform a 16KB BLOAD request increases from 4.18 seconds to 4.4 seconds--only a 5% reduction in request rate. In light of the relatively large 3.8KB/sec BLOAD bandwidth placed on the network, the 36% reduction in message rate seems quite acceptable. Looked at another way, when both the random message test and the file server test are run together, the random messages account for 609 ms. of NadaNet activity in each second, while the file server accounts for 368 ms. per second, for a total utilization of 977 ms. per second, or nearly a 98% network load. Clearly, NadaNet's collision avoidance protocol is quite effective in delivering bandwidth even with a heavy network load!
To get an indication of the effect on performance of running FSERVER on a machine with lower network priority, the ID of its host machine was changed to 10, and the client machine ID was changed to 1. Since the client machine only arbitrates for the network once per request (to queue the request), the primary performance impact would be to the file server as it arbitrates to &POKE each 1KB chunk of data to the client.
As expected, when the network was otherwise idle (no contention), the change in server priority had no effect on the time to process a request. However, when the network was busy (running RAND.MSG.20), the average time to process a 16KB BLOAD increased from 4.18 seconds to 4.8 seconds, a 13% lower rate. Predictably, when the file server arbitrates with lowest priority, the "busy network" impact is 10% greater than in the highest priority case described above. The converse impact of file server activity on RAND.MSG.20 performance remained at -36%, so running the file server at high network priority (low ID number) seems appropriate.
The Test Programs
There are two test programs included in the download which both perform a functional test of FSERVER and illustrate its use.
I tested the file server by PRUNning TEST.FSERVER on seven AppleCrate machines in parallel. In this configuration, all seven instances are queueing requests for the file server, which I run on the "master" machine. This "saturation" test for the file server does a total of 147 requests, covering all the supported commands, involving reads, writes, and non-data operations. With the file server and all clients running at 1MHz, the total time for the entire test is 267 seconds. Wnen the test is run on a single client, it performs 21 requests in a total time of 57 seconds. Note that in the parallel client test, the file server is never waiting on a particular client for its next request, unlike the single client case, so the average time per request is lower.
TEST.FSERVER turns on MONitoring for machine ID 4 and creates the TESTDIR directory. Note that only the first CREATE request will succeed, since all subsequent requests will get a "DUPLICATE FILENAME" error (19), so the code that issues the CREATE request is made tolerant of this error. Then each instance of TEST.FSERVER generates 256 bytes of data and BSAVEs a file whose name is made unique by suffixing the machine ID. It then BLOADs this file and verifies the data, the file address, and the file length. It then DELETEs the file.
Then it creates a small machine language program on page 3 and BSAVEs it (again, with a unique name). It then BRUNs this code at another address and verifies that it ran correctly at the correct address. Again, it deletes the file.
Then it SAVEs itself under a new, unique name, and, after changing the BASIC program start address, it RUNs the newly created copy of itself at the new address. This new copy detects the new start address and runs code that continues by testing VERIFY and DELETE commands. Its final action is changing the BASIC program start address back to $801 and RUNning TEST.FSERVER2.
TEST.FSERVER2 builds two patterns in the HGR and HGR2 frame buffers, then BSAVEs them in a 20KB file (again qualified by a machine ID suffix). The 20KB file is relatively long, requiring segmentation of both the file I/O (into a 16KB buffer) and the network data transfer (in 1KB chunks). After BSAVEing the file, it clears the two hi-res screens and BLOADs the file again. After the BLOAD completes, it flips between hi-res pages rapidly to superimpose the two images to provide a simple visual verification of the first 16KB. It then tests LOCK and UNLOCK, DELETEing the BSAVEd large file in the process. Finally, it issues a STATS command, and prints the statistics returned by the file server.
A study of the code of the test programs will provide numerous examples of how to use the file server.
Alternative Implementations
It is possible to run multiple file servers, each with a unique message queue number. Of course, each file server operates in its own machine’s file system name space.
The current implementation is geared to a network of multiple clients, and relies upon a message server to queue file server requests.
It would not be difficult to modify the server and client interface code for a two- or three-machine network that forgoes queueing (since each client can't have more than one request in the queue at a time) and so can do without the message server. This could be done by having the client code acquire a lock word in the server using &PEEKINC, then &POKE the request into a reserved buffer in the server, then poll the result code while &SERVEing. The server would poll the buffer(s) for the presence of a request and process it when found, as before. Such a scheme would not work well for more client machines, since the server is incommunicado while processing a request.
Links
ShrinkIt disk archive with File Server and test programs